一、dfa 算法简介
在实现文字过滤的算法中,dfa是唯一比较好的实现算法。
dfa 全称为:deterministic finite automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,dfa 中不会有从同一状态出发的两条边标志有相同的符号。
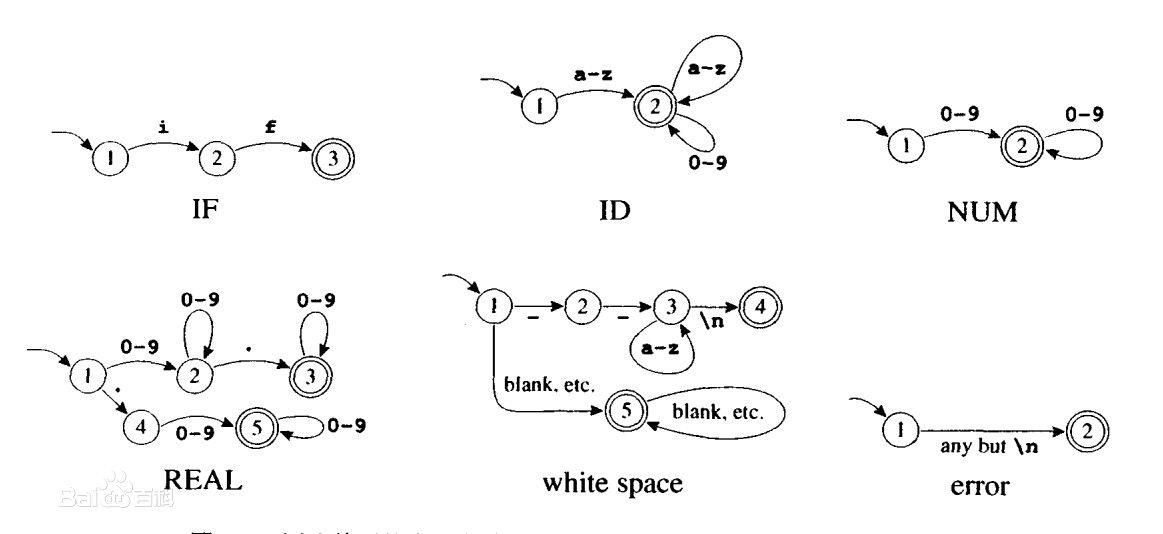
简单点说就是,它是是通过 event 和当前的 state 得到下一个 state,即 event state= nextstate。理解为系统中有多个节点,通过传递进入的 event,来确定走哪个路由至另一个节点,而节点是有限的。
二、dfa 算法实践敏感词过滤
1. 敏感词库构造
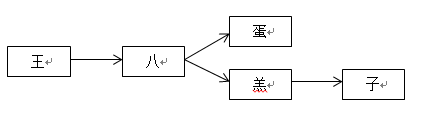
以王八蛋和王八羔子两个敏感词来进行描述,首先构建敏感词库,该词库名称为sensitivemap,这两个词的二叉树构造为:
用 hash 表构造为:

怎么用代码实现这种数据结构呢?
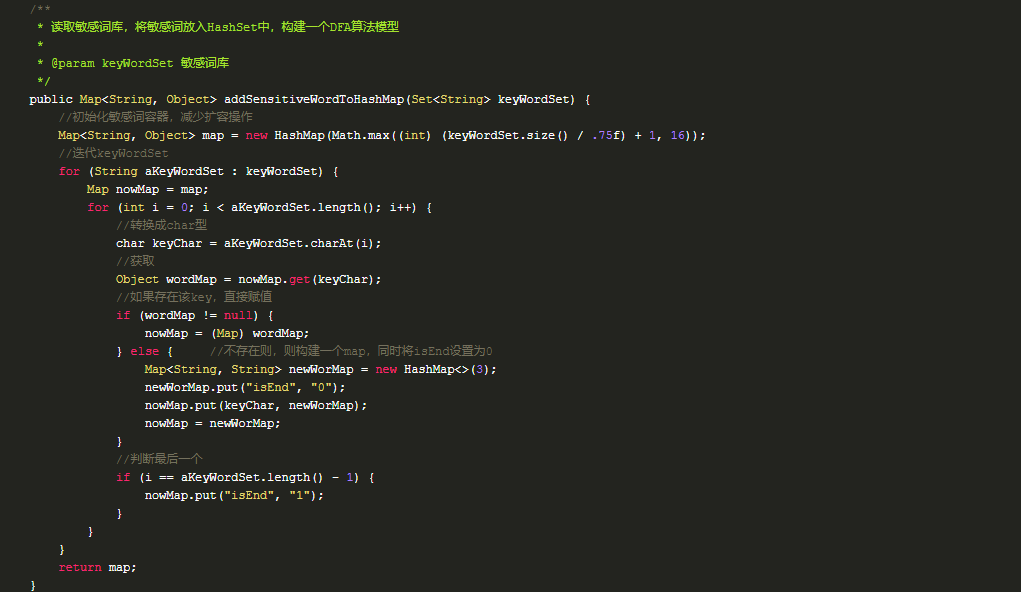
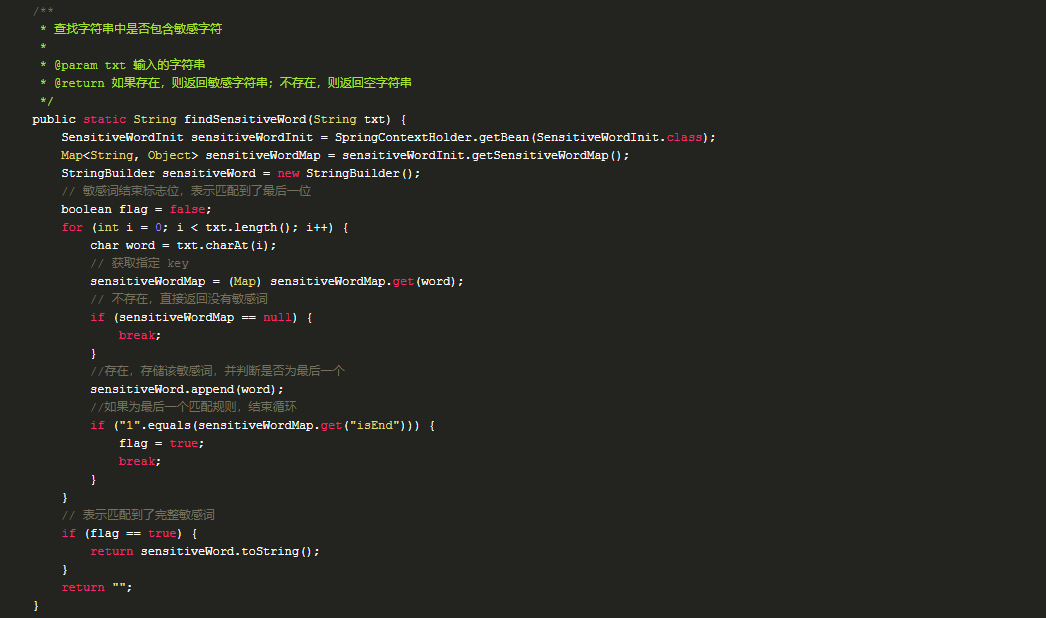
2. 敏感词过滤
以上面例子构造出来的 sensitivemap 为敏感词库进行示意,假设这里输入的关键字为:王八不好,流程图如下:
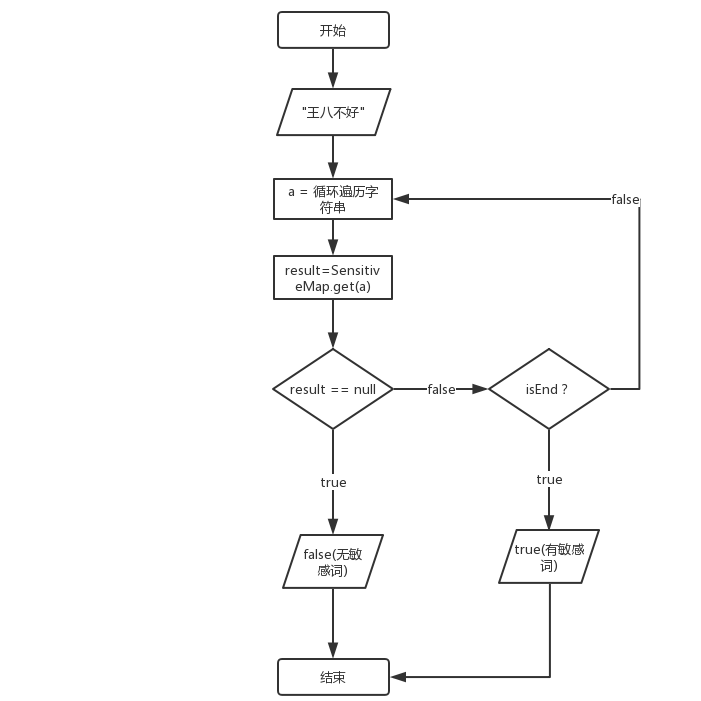
怎么用代码实现这个流程图逻辑呢?
三、优化思路
对于“王*八&&蛋”这样的词,中间填充了无意义的字符来混淆,在我们做敏感词搜索时,同样应该做一个无意义词的过滤,当循环到这类无意义的字符时进行跳过,避免干扰。
来源:博客园 作者:jmcui
原文链接:https://www.cnblogs.com/jmcui/p/11925777.html
【声明】文章来源于网上采集整理,博天堂国际的版权归原作者所有,如有侵权,请邮件反馈yidunmarket@126.com,我们将尽快核实修改。